
Preface
Running an AI model on your own machine is great for writers and not even a bit scary, like you might think. I’ve been testing out a few different things, so I figured I’d give you an overview of the topic and assist you with the entire process. There’s so much to cover on this topic, but let’s start with LMStudio in this first post. I’ll give you the explanation later.
Why would you even do that?
Running a local model is awesome for so many reasons.
- They only cost the electricity to run your computer, no extra money. Writing a book isn’t easy – it results in a bunch of tokens, and if you can get them for free, that’s a sweet bonus.
- Your data stays on your computer, just like Scrivener or MS Word. If you care about privacy, this is a huge deal.
- Local models have their own specialties and unique way of expressing things, so using different models will produce very diverse outcomes. Anything trained on GPT or Mistral will be extremely verbose, and those proprietary models have their overused “isms”. Changing it up makes things more diverse.
- Sometimes they censor those massive models, and if you try to write something that violates their rules, you’ll get an error. Obviously, as a writer, sometimes you want to write about stuff like violence or sex, or research topics that a model might think are not cool. So, if you’re writing a thriller, you might want to figure out how this toxin works and if it’s possible to whip it up on your own. This is just a dull example I made up for this blog post.
Now I’ll introduce you to a “runner” program for AI models on Windows, but it’s also available for Mac and Linux.
What do you require?
Running a local model can be hardware-intensive, but it’s not too bad even on an old laptop.
I had a machine with 8GB RAM and a 1050TI to begin with. 7B models ran fine, and there are good ones available.
What matters for LLMs is how much VRAM you got, and my old card had 4GB. The 7B model maxes out at 8.6GB, so my system had to shuffle some to my regular RAM.
Typically, you can just add 30% to the model size for the RAM it needs. The more VRAM your card has, the larger model chunk it can handle. It’s way faster than your regular RAM.
A RTX 3060 with 12GB VRAM can comfortably handle a 7B model, and even most of a 13B model (and there are tricks to make it fit, but I’ll talk about that later). The king of consumer graphics cards, a 4090, has a whopping 24gb.
If your motherboard allows it, you can double up on the same card for either 24GB RAM with a second 3060 or 48GB with a second 4090.
The important thing is that you’d need the same card you already have for the second card to work. Unfortunately, you can’t mix a 3060 with a 4090.
To use LMStudio, you’ll need either Windows, Mac, or Linux. All operating systems have their own clients.

Where can I grab LMStudio, and what’s the next step?
Just go to their website at https://LMStudio.ai/ to download LMStudio.

It’s freeware, so you don’t have to spend a dime on all the features. Get the program, no subscriptions or in-app purchases or unlockable stuff.
So you’ve downloaded LMStudio for your operating system. What’s next?
Let’s get this party started! It doesn’t look good, unless you’re a GenXer like me who’s nostalgic for BBSs, but don’t let that bother you. The start tab is where you land when you open the app. There’s a search bar, and a few featured models.
Why don’t we start with something small? You just want to mess around and see how this all works. Type “mistral” in the search box, and you’ll see a list of models. See if you can find a TheBloke/Mistral model. The very first one on the list is the one we’ll use for our test run.
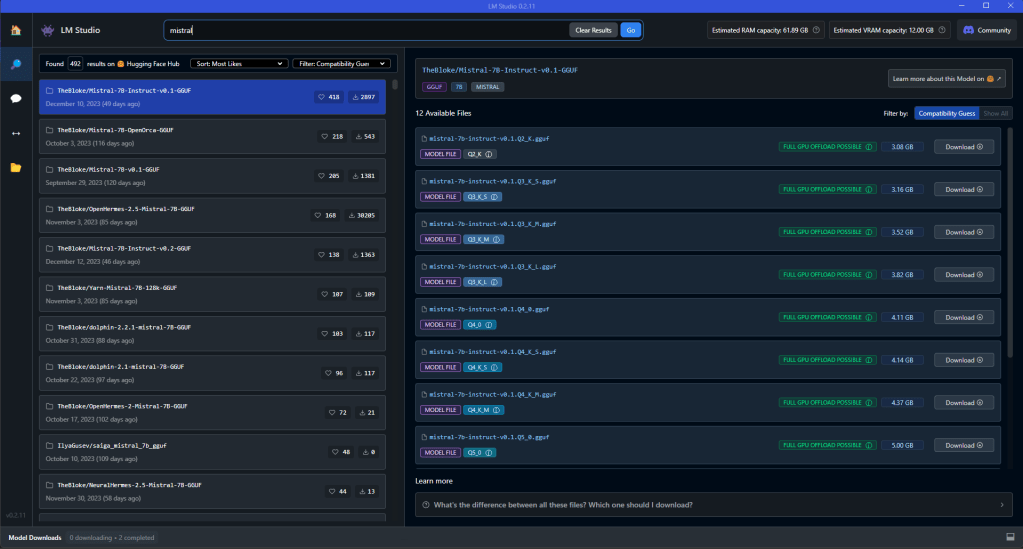
Depending on your graphics card, we’ve got some options. Check them out on the right. What runs well on your system depends on your VRAM, and the model we choose will use a specific amount. The Q8 model uses 8 bits, so it’s super precise. This is a good choice for someone with 8+ GB VRAM. If you’re short on VRAM, go for the Q5 since it uses less RAM. Note: let’s try to use VRAM instead of regular RAM for the complete model, or at least most of it. If you have less than 8GB VRAM, try smaller quants like Q4 K_M. If you have 12gb, like me, go for the Q8. now download it. And chill. And grab a coffee. And take the dogs for a walk. Huggingface, the site that hosts local models, can be super slow, kind of slow, or just plain terrible.
Now you’ve got your first model downloaded and you’re good to go!
How can I make this work?
Look at the speech bubble icon on the left.

You’ve probably seen this before if you’ve been using chatgpt. There’s an input field and chat, plus some weird stuff on the right that we’ll go over together.
Start by loading your brand new model.

This is Mistral. Each model has its own set of instructions. Go to the Huggingface site and see which one they use.
Pick the one that best fits, or use “LMStudio default”.”
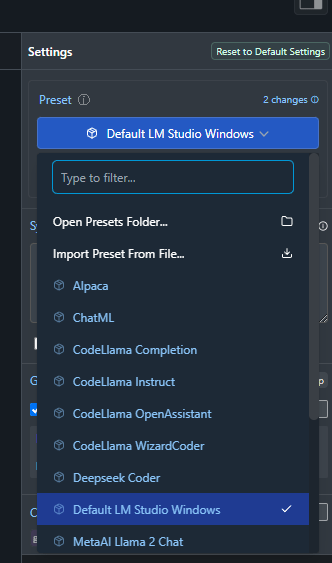
Offload as much as you can into the VRAM.
Open your task manager, go to the “performance” tab, then click on “GPU”.
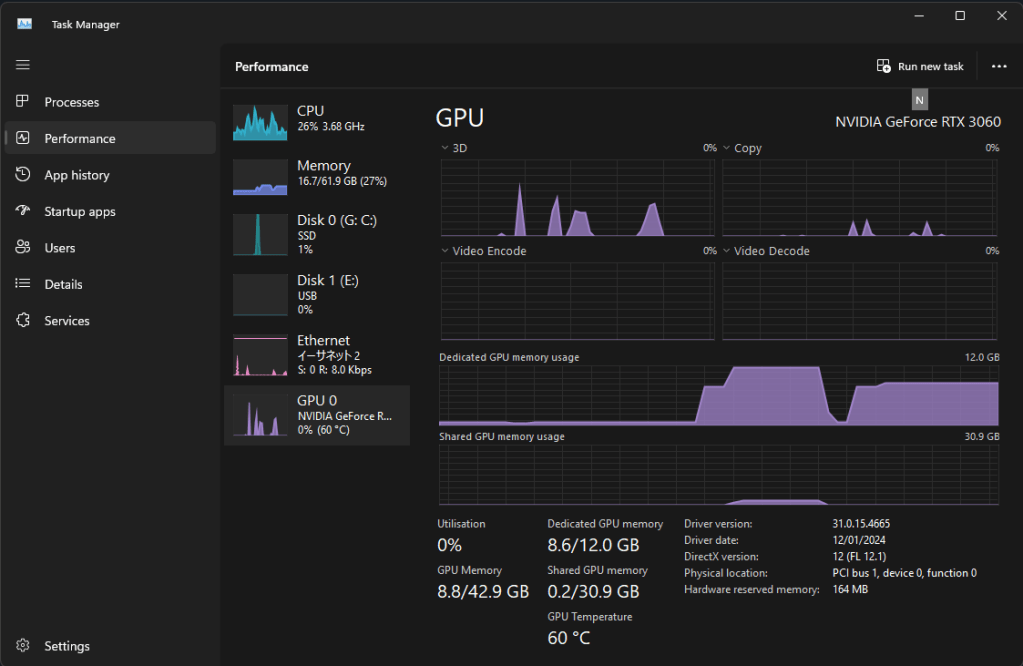
Head back to LMStudio and look at the right side of the screen.
First, click “GPU Offload”. Just set n_gpu_layers to a small value, like 5, then go back to taskmanager and see how much VRAM is being used up. Keep increasing the amount in 5er steps until the RAM stops going up. The 7B model on my RTX 3060 only needs 8.6GB RAM, so 35 layers should be plenty (I think 28 is the exact number it needs to fit in VRAM).
Set the length of the context. Mistral can hold up to 32768 tokens in its memory. More is better, but 32k, while impressive, hurts performance. Set it to 16384 for now. Reload the model and switch to the chat tab. Try it and see if you like it.
This is how you run a local model in LMStudio, basically. Lots of excellent models are out there for it. The GGUF format is used, with options for capped decimals to save on RAM and run faster.
Which model should I use?
Now that you’ve got the basics, experiment with settings like GPU offloaded layers, context window size, and presets. Just search and download any model you want, test it out, and see how well it does.
Great models for beginners:
- Airoboros
- Mistral
- Mythomist
- Mythomax
- Yi
- Writing Partner
- Open Hermes
- Zephyr
- Orca
- Dolphin
Give them all a go, have fun experimenting, and don’t worry about all the settings stuff. Everything you need to know is in this blog post.
Next time, I’ll discuss using LMStudio as a server for external apps like NovelCrafter.
