
I wrote about my motivations and goals for Ninereeds and introduced the architecture of the model, what makes it different from transformers and why. Since I posted those, I finished the training material (as far as training material can be considered finished for a model that’s not researched properly yet) and ran training on it. I did this in the past already, and would like to tell that story to provide some background for the reports I’ll post here soon, along with my thoughts on them.
Opening Image
So a while ago I experimented with OpenClaw, like many other people, and then Hermes Agent. I had it set up in a way that let me talk to it via Discord. Around that time, I also learned about the BDH architecture and saw it was open-sourced on GitHub. I asked myself: Can I train a BDH model locally at all, and if so, what data does the architecture respond to? And then I asked my agent, run by Nemotron 120B – surely it could find out more about it on the net. But Nemotron didn’t just look up the info. It interpreted my request as a direct command. It cloned the BDH repository, fetched a dataset, and launched the training.
Watching this was interesting. My primitive agent environment had successfully prepared the project all on its own, which was impressive, given that this Nemotron was a relatively simple 120B model. What this showed was also proof that I could train and run the model. The output itself didn’t matter at that point; it was a test run, a proof of concept, and it had passed. Now I was hooked.
Set Up
Tiny Shakespeare is a tiny training dataset comprising Shakespeare’s texts – WYSIWYG. Nemotron picked this set to see if everything works, and it did. I could run inference on it.
“To be or not to be ggg lllll aaa”
Training was possible, and the model could produce language-like output. The pipeline worked. What about the architecture? What about the model itself? Now I was determined to find out.
Theme Stated, Foreshadowing
I did not know what to train it on, and Pathway didn’t talk about the topic anywhere. A quick sweep of the net surfaced nothing substantial, so it was on me to figure things out. The next step was: train it on a real training set. Tiny Shakespeare was really just a test of the training mechanism itself. It taught nothing.
There are many datasets out there; I went with BabyLM, in 2 sizes: first the 10M parameters, then the 100M set. And it worked: BDH learned the shape of words and the rough shape of sentences.
“the moon dog fly water”
This was better than Tiny Shakespeare – real language, albeit nonsensical. Maybe the model needed more data? Transformers learned by generalising from huge amounts of it, so it was a reasonable hypothesis; and since training worked on my machine, I had to follow deeper into the rabbit hole. It had eaten a bigger dataset, and it had improved. Not in the way I had hoped to see yet, but progress was progress. More data improved local token plausibility, but it didn’t automatically produce relational understanding. The model could emit familiar words without actually organizing them into a stable concept system. This was the first sign that BDH might require a different teaching strategy from standard large-scale text immersion. But following hunches isn’t how I perform experiments, and the question was still open: will more data help it break through the ceiling, or do I need to come up with a different idea? Spoiler: I did follow that hunch anyway, and the failure became a data point of its own.
Catalyst and Debate
The next experiment would show whether pushing harder would help. I downloaded the story subset of Cosmopedia, another training set for LLMs, and extracted 200.000 stories from it. Training this did actual damage:
“a dog … the the the the the”
Performance had degraded significantly. The model had converged toward repetitive token sequences. At least in this configuration, larger-scale text exposure appeared harmful rather than beneficial.
Its next token prediction homed in on the most probable sequence. This stage was important because it had real diagnostic value. The result had been failure, but this failure was instructive: BDH couldn’t be trained by showing it huge amounts of data that didn’t also teach it the structure it needed. In fact, it appeared to damage whatever fragile internal organization had already formed.
The lesson from Cosmopedia was that unrestricted natural-language volume was not helping. The architecture did not seem to infer stable knowledge from broad text exposure alone; data quality, structure, and sequencing were likely more important than raw dataset size.
Break Into Act 2
After the Cosmopedia failure, the approach changed completely. Instead of searching for a better large corpus, I created a custom curriculum by hand. This became the “phase 1 to 5” training set (which since has evolved and changed significantly). The underlying idea was simple: If the architecture does not build concepts reliably from broad text exposure, then concepts must be introduced deliberately, in order, and with controlled language. Reading up on Hebbian learning seemed to support the hypothesis. There was already no turning back for me. I had started this adventure, and now I’d see it through.
I built the curriculum in phases, each phase teaching a different level of conceptual structure. Core design choices included tiny, repeatable Q-and-A units, concrete language, firm control over vocabulary introduction, stable conceptual arcs inside each file, and cumulative dependencies instead of random exposure.
The Seismic Test
I ran an early, large test before the corpus had its current fine-grained file layout. Each phase existed as a combined file rather than the more carefully split and indexed version now in the repository. The model was trained through all five phases in sequence, which became an important stress test for the idea.
The rough results (a still primitive probe that measured how well the model could activate concepts) were:
- – Phase 1: 6/9
- – Phase 2: 4/9
- – Phase 3: 9/11
- – Phase 4: 4/9
- – Phase 5: 4/9
These scores did not mean the project was done, but they did mean something important: the custom curriculum could move the model measurably, some phases were clearly working better than others, and performance was uneven in a way that suggested structural causes, not just random variance. This was enough to justify a careful review of the curriculum itself.
A Lesson Learnt
Looking back at the curriculum after the seismic test made me realise that dependency ordering might be crucial. Yes, the foreshadowing from “the moon dog fly water” paid off. The issue was not only whether the model had seen a word before, but whether it had seen the right conceptual supports before encountering a more complex concept: bee before honey, honey before beehive, beehive before jar of honey. This is more than vocabulary order. It is in concept graph order.
That insight led to the current cleanup and reorganization work: splitting the phases into many individual files, creating a canonical training sequence, adding a concept index, generating a dependency graph, and tracking vocabulary introduction in a vocab bank.
The curriculum became much more explicit after this point, a shaped path through a dependency network.
From Text Completion to Chat
Another major shift in the project was a change in format philosophy. Early language-model experiments can easily drift toward plain text completion because that is the easiest format to generate in bulk. But the actual goal of the project was not to make BDH continue text. The goal was to make BDH chat and to support some reasoning within that chat. That realization led to introducing a proper chat format from the start. This was not a cosmetic decision. It was a training-shape decision. The curriculum now aims to teach at least three things at once: concepts, controlled language, and interaction format. The model can now answer “Tell me about dogs” instead of finishing “A dog is…”
The Wiki Layer
The next major idea was to build a knowledge base for a first grader. That idea became the wiki layer, designed to do something different from the phase curriculum. The phases teach anchoring, vocabulary control, compact concept introduction, and tightly constrained response structure.
The wiki adds broader but still shallow knowledge, relational and social context, and other topics, along with more natural explanatory prose. The target is not expert knowledge; it’s the broad, ordinary, connected knowledge that a child uses to understand daily life. This distinction matters. The curriculum teaches the model to see; the wiki teaches it to relate. That’s why the wiki is intentionally broad but not deep.
And this is where we are now:
- 01_language
- grammar
- vocabulary
- teaching_stories
- triplet_stories
- 02_thinking
- reasoning
- grounded_stories
- 03_education
- wiki
- 04_philosophy
The full curriculum currently contains over 47,000 training files organized into four major domains. Vocabulary is introduced in carefully controlled phases, followed by reasoning, educational material, and philosophical concepts.
The corpus is still growing. Every training campaign shows additional problems, and now my focus has also shifted from “train a little BDH model” to “figure out the laws that govern learning in models based on the BDH architecture”. My training data has developed, and so has my methodology. I can ping specific concepts and perform an MRI of the model, label every cluster and diagnose problems not by staring at a loss curve (that only tells me whether next token prediction improved), but by testing concepts in a controlled way and taking snapshots. After each training epoch, I run an inference script that tests the model by asking it questions like “What is a dog? Does a cat bark?”, and unlike a Transformer, where knowledge is distributed across many parameters and difficult to localize directly, BDH models have very sparse activation; only a fragment of their neurons (weights) light up. If cat and dog live in the same cluster, and this cluster contains mammals, they landed in the correct neighbourhood, and if bark lies closer to dog than cat, there’s no content bleed.
The MRI catches this and even creates a picture like this one:
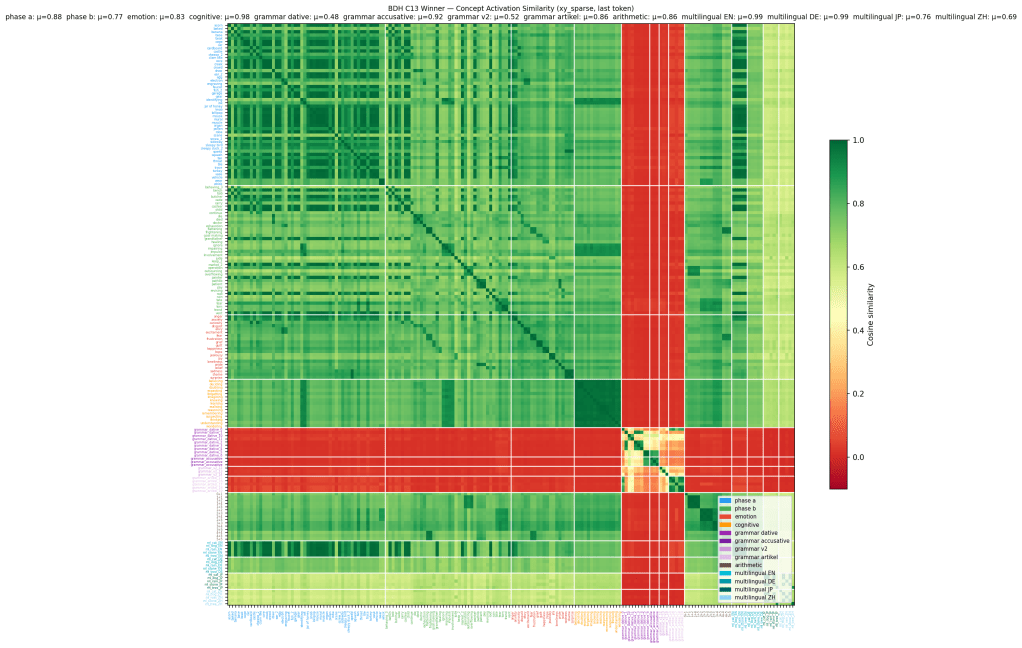
This is the MRI of a BDH model after training campaign 13. Each square compares the activation patterns of two concepts. Green shows similar representations; red shows separation. The large red band corresponds to grammatical concepts that the model has learned to keep distinct from semantic concepts. The red band has internal structure: accusative, dative, article, and V2 are all similar to each other but strongly separated from semantic concepts. One interpretation is that the model has begun to represent grammar as a coherent category of knowledge rather than as isolated facts.
The training data was 4-lingual: English, German, Japanese and Chinese, and Ninereeds, the model, seemingly decided that English and German are more similar to each other than to the two Asian languages. I’ve since adapted my curriculum.
This weekend will see campaign 14, which is all about language acquisition (specifically, about learning accusative and genitive relations in sentences) and in my next posting, I’ll explain what a campaign is and what training has shown thus far.
